
-1.png)

Table of Contents
Like this article?
Subscribe to our Linkedin Newsletter to receive more educational content
Subscribe nowCustomer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Integrate with your existing monitoring tools to create simple and composite SLOs

Rely on patented algorithms to calculate accurate and trustworthy SLOs

Fast forward historical data to define accurate SLOs and SLIs in minutes
Customer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Enforce quotas and track results
SLIs provide a useful guardrail and reliability perspective for confidently enforcing resource usage limits to constrain Kubernetes costs. This can be especially useful when discussions of enforcement levels lack evidence or create tension between administrators and development teams.
Data from metrics provide precise resource utilization figures, but SLIs add the necessary context to understand the real impact on reliability and user experience. Used together, they remove the guesswork when establishing safe resource enforcement limits.
A common way for cluster administrators to avoid unconstrained cluster usage and generally enforce limits on individual teams is through the use of resource quotas and limit ranges:
- Limit ranges are policies that enforce resource usage limits for individual objects within a namespace.
- Resource quotas are policies limiting the aggregate use of all resources by a single namespace.
Used together, these allow cluster operators to enforce sensible per-workload limits and fair usage of the entire cluster by namespace.
Administrators can cap spending by applying default resource usage limits on containers for teams that schedule workloads without setting resource request and limit values. This can be done by defining a LimitRange object as follows:
apiVersion: v1
kind: LimitRange
metadata:
name: default-limits
namespace: production
spec:
limits:
- type: Container
default: # Applied if no limits are set on the container
cpu: "500m"
memory: "256Mi"
defaultRequest: # Applied if no requests are set
cpu: "100m"
memory: "128Mi"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "50m"
memory: "64Mi"
Example LimitRange object enforcing default and maximum values for individual containers
Similarly, cluster operators can limit spending at the namespace level by defining a constraint on total namespace resource usage via a ResourceQuota object:
apiVersion: v1
kind: ResourceQuota
metadata:
name: team-quota
namespace: production
spec:
hard:
requests.cpu: "10"
requests.memory: "20Gi"
limits.cpu: "20"
limits.memory: "40Gi"
pods: "50"
services: "10"
persistentvolumeclaims: "15"
Example ResourceQuota object enforcing a ceiling of resource usage across an entire namespace
Defining these limit levels can be contentious, so SLIs provide a valuable source of evidence for justifying what is actually required.
When examined over an appropriate look-back window, SLI data can demonstrate the reliability experience resulting from the metrics data, such as average and peak resource utilization. SLI data will also highlight any trends in reliability, especially when viewed over multiple right-sizing exercises or changes in service demand. With additional consideration of headroom within the related SLO bounds, this informs discussions of appropriate enforcement levels.
SLO error budgets also provide useful insight here into the optimal limits on resources and spending. For example, if a service's error budget burn rate exceeds a defined threshold, or if resource utilization is close to the pod’s limit ranges or the namespace’s resource quota ceiling, then this indicates that the quota may be constraining the service's ability to maintain its SLO. Conversely, a service with a consistently healthy error budget well below its quota ceiling is a signal to lower the limits.
As a simple example, consider an analysis that indicates that a container is using 200m of CPU while it requests 2000m. This looks like an obvious right-sizing opportunity, yet that metric alone does not tell application teams whether it is safe to reduce the request value in the pod spec. The SLI, however, answers that question: If p99 latency is healthy, the CPU throttling rate is near zero, and the error budget burn rate is stable, the SLI data confirms genuine headroom. If p99 is elevated and throttling is non-trivial, the SLI reveals that the low average is deceptive and that the container is hitting its limit during peaks that the average masks.
This is a key aspect of SLIs. They capture the integrated effect of all peaks and troughs on the user experience over a rolling window.
Monitoring error budget burn rates and alerting at different levels of error budget consumption lets teams proactively ensure that resource spending is proportionate while validating that enforced resource usage levels are not impacting reliability.
The following Nobl9 dashboard example shows how teams can monitor error budgets:
 Example error budget dashboard summary showing error budget status for different services
Example error budget dashboard summary showing error budget status for different services
Similarly, individual service health can be analyzed in terms of error budget burn rates and SLO annotations showing events or configuration changes (e.g., new resource limits) and used as input to appropriate right-sizing of enforced resource limits. An example Nobl9 dashboard showing service health by error budget burn rate helps illustrate this.
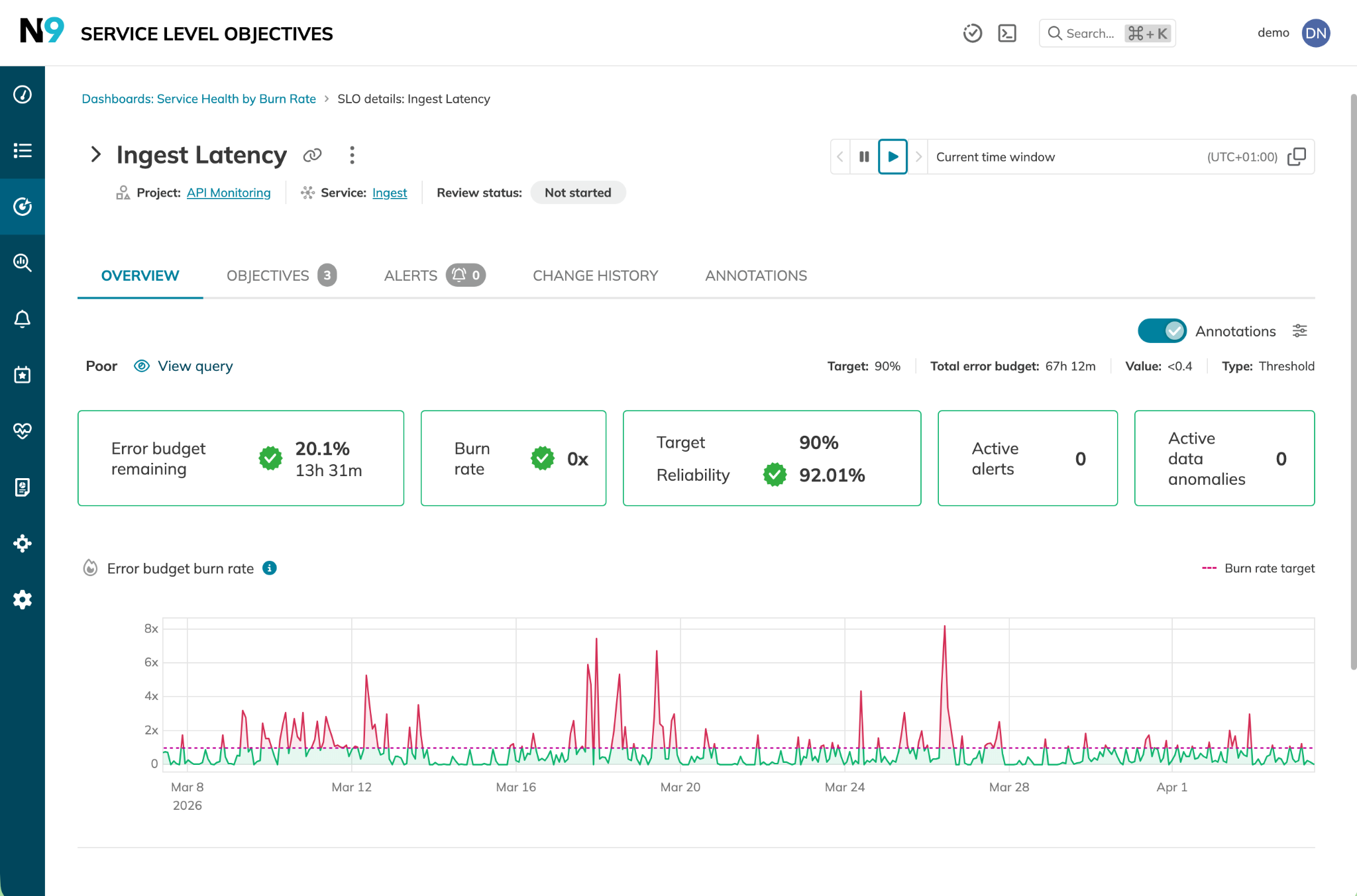
Example service health dashboard showing error budget burn rate
These examples show how costs can be managed by enforcing limits on resource usage, how SLI data is used to right-size those limits based on real usage, and how SLO compliance is used to verify that the limits don't compromise reliability.
Navigate Chapters: