
-1.png)
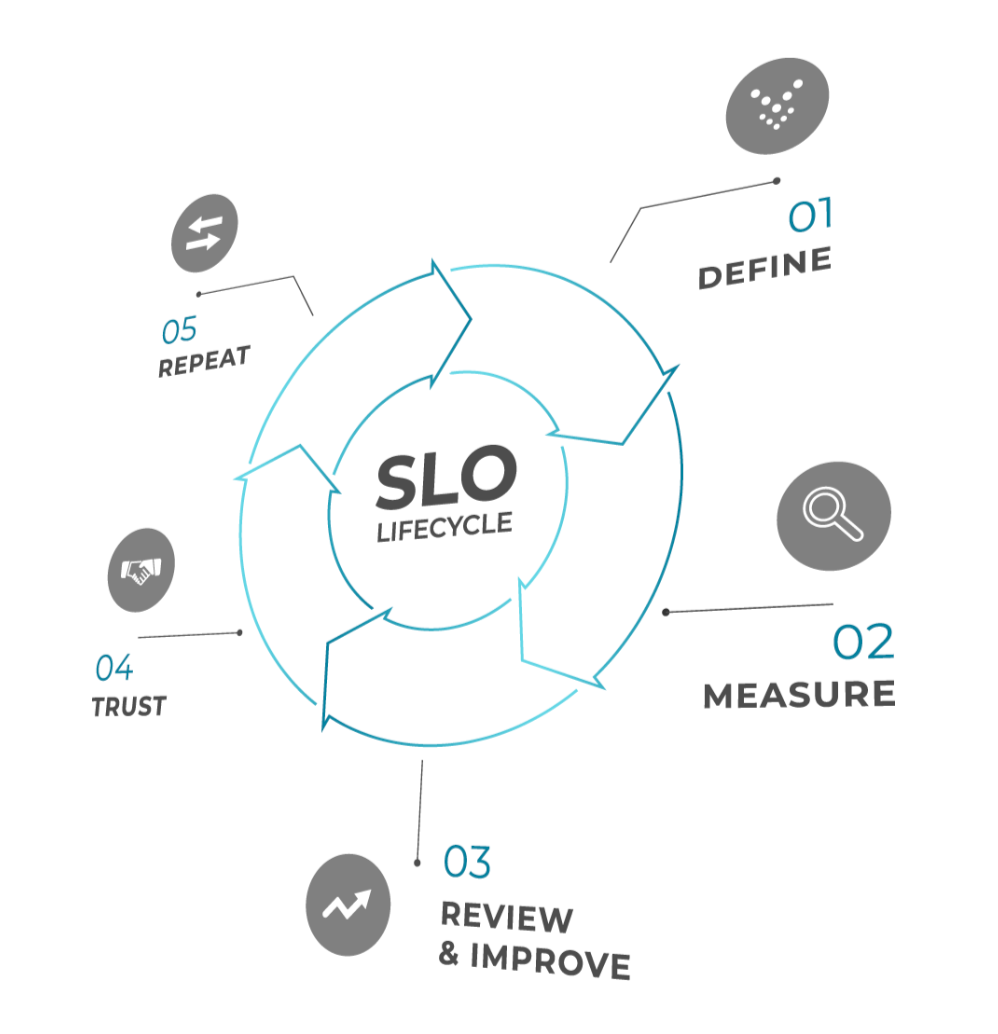
Table of Contents
Like this article?
Subscribe to our Linkedin Newsletter to receive more educational content
Subscribe nowCustomer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Integrate with your existing monitoring tools to create simple and composite SLOs

Rely on patented algorithms to calculate accurate and trustworthy SLOs

Fast forward historical data to define accurate SLOs and SLIs in minutes
Five proven SLO framework best practices
An effective SLO framework requires a strategy that encompasses the entire SLO Development Lifecycle. The five best practices outlined in the sections below enable organizations to design a framework tailored to their use case while integrating proven best practices for SLO definition, implementation, and continuous improvement.
Define your business case
Starting your organization's SLO journey with a compelling SLO business plan can significantly enhance the adoption of an SLO framework. A good business plan helps engage relevant stakeholders early in the process. The reusable business case template from the SLO Development Lifecycle (SLODLC) is an excellent starting point.
A quality SLO business plan contains the following key features:
- A high-level vision for what the business wants to achieve and why
- Identification of stakeholder groups with their roles and responsibilities
- A definition of the desired business outcomes
- A business investment case for addressing the technology challenges
- Dependencies within your organization
- Initial scope, any constraints and exclusions, and relevant milestones
- Risks and opportunities
A business plan for each customer-facing service will clarify the business goals for all stakeholders. It also highlights key roles and who is responsible for what. Additionally, a well-structured plan can justify the investment of time and effort to deliver the desired business improvements. The Business Case Worksheet records these specifics. The example sections below are a good reference for how a team may define each section.
High-level vision example:
The company operates a public e-commerce website that sells luxury travel experiences, with advertising for additional services. The website is hosted on a cloud-based managed Kubernetes platform. Our vision is to scale the platform, offer a wider range of personalized services, support more locations, and increase the reliability of operations to facilitate a faster release of new features.
Business investment case example:
Projected costs:
- Internal SLO learning and upskilling: -35K USD
- SLI/SLO analysis, collection, and refinement: -50K USD
- SLO publishing, dashboard, and reporting: -25K USD
Earnings and savings:
- Increased SRE staff productivity and reduced turnover: +100K USD
- Improved feature rollout velocity: +75K USD
- Increased revenue from customer retention: +25%
A shared definition of desired business outcomes will ground the business plan in tangible benefits and emphasize the specific pain points it will address, such as customer engagement, developer burnout, or reduced velocity in delivering new features.
With the Business Case Worksheet, teams have a consistent way to define an SLO business case that they will repeat for each service. The SLODLC Business Case Example provides a detailed reference to help teams understand what a good SLO business case looks like.
Understand your services and users
The SLODLC Discovery Worksheet provides a comprehensive guide to conducting the next step, service discovery and analysis.
To build and apply effective SLOs, you need a detailed understanding of your service. Pay particular attention to appreciating how a user interacts with your service from start to finish - otherwise known as the user journey. Note that not all services have external users, the only user of a service might be another internal service! Prioritizing this perspective will inform decisions on where to focus, what to measure, and which levels constitute acceptable versus unacceptable performance.
Stakeholder workshops can be especially beneficial in this context to gather input from the relevant audience, align on expectations, and foster broad buy-in to the business case goals. Those SLO goals should be the defining aspect that helps prioritise the right metrics for the service performance levels that matter to your service users.
With a clear picture of your user journeys, you should then focus on identifying all the system dependencies to which user interactions are subject. Dependencies can arise from technical components or related user workflows.
First, establish where the technical and architectural dependencies occur. Then, note the interrelated dependencies within the user journey. Once these are documented, revisit your initial prioritization and ensure it accurately reflects your analysis of dependencies and any constraints affecting them.
Teams can user dive deeper into journey representations in the Discovery Worksheet Example:

Example: identifying architecture dependencies with key user journeys
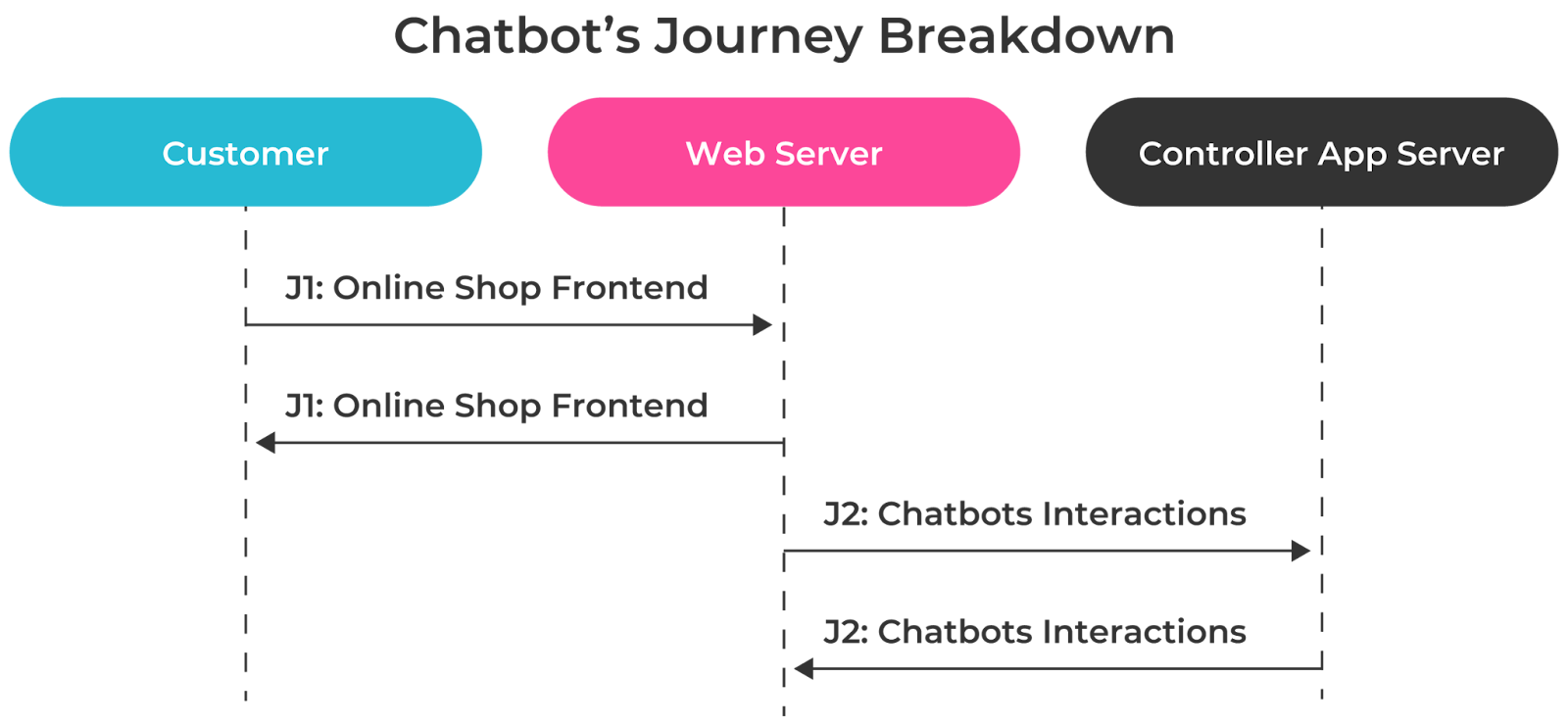
Example: mapping specific user journey flow details for SLI selection
When user journeys and dependencies are documented, you should then take time to observe your system’s current behavior, data sources, and reliability history. Ensure you are producing dependable monitoring and observability data that provides the necessary information for managing incidents and outages.
Examine historical outages and resulting post-mortems. Then, use the findings to produce case studies that underpin your choice of SLIs, your SLO design, and your drive to address existing weaknesses through SLO business improvement. This process also provides an opportunity to review the quality of your observability data, related retention policies, and any gaps.
The Discovery Worksheet guides you through the above process. It identifies and captures both the service's business and technical contexts and provides a structured approach to capturing the following key outcomes for this stage:
- Service description, owners, business expectations, and existing pain points
- Users, user journeys, user expectations, and priorities
- Architectural dependencies, constraints, and process governance
- Outage and reliability history with relevant case studies
- Available data sources, alerting tools, policies, and escalation paths
Define service level indicators and objectives
The Discovery Worksheet provides all the input needed for the next stage: designing and crafting SLIs and SLOs.
The outcome of this stage should be a documented and agreed-upon starting definition of your SLIs, SLOs, and error budgets. The SLODLC Design Worksheet Template and Example Design Worksheet provide resources to help engineers deliver these objectives.
Determining the right SLIs and their associated SLOs is an iterative process that needs to adapt to stakeholder feedback. SLIs and SLOs will be subject to regular review and fine-tuning, so they will vary accordingly. Having a defined owner for each SLI helps here.
A good SLI reflects what is important to stakeholders and does so in a meaningful way. These key technical indicators of service health must be specific, simple to understand, user-focused, and an aggregation of multiple services if possible. They must also be challenging to meet.
A good SLI should have a high-level, user-centric specification with corresponding implementation details on how to measure it, as shown in the example below.
Specification:
The ratio of user product page load times not exceeding 75 milliseconds
Implementation:
The ratio of user page load times not exceeding 75 milliseconds as measured by server latency log metrics - note these will exclude failed front-end queries
The final element of your SLI is the definition of reliability to be inferred from your given metric. Depending on your service type, e.g., request-driven, pipeline, or storage, the critical metrics forming your SLIs may include latency, traffic volume, error rates, and resource saturation, as shown in the following SLI menu table of meaningful metrics (taken from the Google SRE handbook):
|
Request/Response SLIs |
Data Processing SLIs |
Storage SLIs |
|
Availability |
Coverage |
Throughput |
|
Latency |
Correctness |
Latency |
|
Quality |
Freshness |
Durability |
|
Throughput |
Consequently, the reliability indicator - the SLI itself - measures the metric over a given time window, e.g., the ratio of successful user requests to total requests over a 4-week rolling time window.
SLOs can then be defined as your target, or objective, for the level of service quality you deem appropriate for the service being measured by your SLI. Initial SLOs should be achievable immediately, and aspirational SLOs can follow later.
Your knowledge of the customer journey and its priorities, as documented in the Discovery Worksheet, will inform the development of appropriate and realistic SLO targets.
Your service SLO could then look like this example:
|
SLO Type |
Objective |
Time Window |
|
Availability |
98% |
Rolling 4-week |
|
Latency |
95% product page loads < 75 ms |
Rolling 4-week |
Aspirational SLOs can also be implemented to extend your organization’s ambitions for service reliability and help focus engineering and improvement efforts. However, effective SLOs must be both relevant and verifiable through testing. This could extend your SLO definition as follows:
|
SLO Type |
Objective |
Time Window |
|
Availability (achievable) |
97% |
Rolling 4-week |
|
Availability (aspirational) |
99% |
Rolling 4-week |
|
Latency (achievable) |
95% product page loads < 75 ms |
Rolling 4-week |
|
Latency (aspirational) |
98% product page loads < 75 ms |
Rolling 4-week |
Customer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Composite SLOs take your individual SLOs a step further. By combining separate SLO targets into a single representative objective, they offer a way to represent the reliability of an entire multi-system application or service in a single SLO. For example, a three-tier web server may have SLOs for the front-end, mid-tier, and back-end services.
By combining these constituent SLOs and appropriately weighting their contribution with their criticality to the overall experience, teams can create a single overall reliability target in a singular composite SLO, as shown below:
|
Composite SLO |
||
|
Component SLO |
Weight/Criticality |
Normalized Weight |
|
Product Catalog |
0.5 |
15% |
|
Shopping Cart |
0.4 |
25% |
|
Checkout |
0.1 |
5% |
|
Payment Gateway |
1.0 |
45% |
|
Purchase Confirmation |
0.2 |
10% |
Tools such as Nobl9 are agnostic to your existing chosen telemetry and observability platforms. They utilize existing data sources to enable teams to easily and dynamically define both simple and composite SLOs. Review the complete list of Nobl9 data source integrations for more information.
Teams set error budgets to determine how much daily deviation from their SLO target is acceptable. These budgets provide a level of acceptable service quality deterioration or error rate.
Error budgets should have a corresponding error budget policy to enforce compliance and define the consequences of exhausting the budget. All stakeholders should agree on this policy, which outlines the actions necessary to maintain a reliability balance. The policy should outline the actions for restoring service quality (when error budgets are exceeded) and, conversely, the actions and tolerable level of risk for service enhancement work (when error budgets are in credit or surplus).
The SLI/SLO Specification Template from the SLODLC provides a way to capture a complete definition of your SLIs, SLOs, and error budget policies. It will be a living document, subject to continual review and refinement of specifications. The supporting Example SLI/SLO Specification provides a valuable reference for a complete specification.
Implement your service level objectives
Having defined your SLO specification, the next stage is to roll it out and activate it. At this stage, teams begin collecting SLIs that provide insights into their system's behavior while publishing SLO targets for the wider organization. These steps also enable teams to enforce their error budget policies.
You will need to collect the correct data to ensure that you can measure your defined SLI. This could include success versus failure rates, latency measurements, request duration times, or similar metrics. You will need to utilize a wide range of data sources, including server logs, monitoring systems, observability data, client-side telemetry, and existing dashboards. The key here is to start simple and determine the approaches with the least engineering effort.
Publishing objectives is an integral part of this phase. In doing so, you raise awareness of your SLO strategy progress against your stated SLO goals and further drive stakeholder engagement. Clear communication roles and responsibilities should be in place to achieve this. Additionally, the method and location of publication must be clear. Publishing SLOs is a dual-step process: deploy the SLO code specification to your SLI metrics layer and then display your SLO data and compliance level in a dashboard or similar reporting presentation layer.
To help automate deployment and configuration management, Nobl9 provides a CLI tool to deploy SLOs-as-code: sloctl. It is available as both a standalone binary and a dedicated Docker image. See the releases on GitHub for downloadable binaries and the sloctl user guide for installation steps.
The sloctl CLI empowers you to automate your SLOs as code. A quick look at just some of the built-in help pages illustrates what the CLI can do.
The get sub-command retrieves resource information:
$ sloctl get --help
Prints a table of the most important information about the specified resources.
Usage:
sloctl get [command]
Available Commands:
agents Displays all of the Agents.
alertmethods Displays all of the AlertMethods.
alertpolicies Displays all of the AlertPolicies.
alerts Displays all of the Alerts.
alertsilences Displays all of the AlertSilences.
annotations Displays all of the Annotations.
budgetadjustments Displays all of the BudgetAdjustments.
dataexports Displays all of the DataExports.
directs Displays all of the Directs.
projects Displays all of the Projects.
reports Displays all of the Reports.
rolebindings Displays all of the RoleBindings.
services Displays all of the Services.
slos Displays all of the SLOs.
usergroups Displays all of the UserGroups.
The apply sub-command lets you apply new configuration from a YAML definition:
$ sloctl apply --help
The apply command commits the changes by sending the updates to the application.
Usage:
sloctl apply [flags]
Examples:
# Apply the configuration from slo.yaml.
sloctl apply -f ./slo.yaml
# Apply resources from multiple different sources at once.
sloctl apply -f ./slo.yaml -f test/config.yaml -f https://nobl9.com/slo.yaml
# Apply the YAML or JSON passed directly into stdin.
sloctl apply -f - <slo.yaml
# Apply the configuration from slo.yaml and set project if it is not defined in file.
sloctl apply -f ./slo.yaml -p slo
# Apply the configurations from all the files located at cwd recursively.
sloctl apply -f '**'
# Apply the configurations from files with 'annotations' name within the whole directory tree.
sloctl apply -f '**/annotations*'
# Apply the SLO(s) from slo.yaml and import its/their data from 2023-03-02T15:00:00Z until now.
sloctl apply -f ./slo.yaml --replay --from=2023-03-02T15:00:00Z
More sophisticated commands like managing budget adjustment events are also possible, e.g:
sloctl budgetadjustments events get \
--adjustment-name=sample-adjustment-name \
--from=2024-09-23T00:45:00Z \
--to=2024-09-23T20:46:00Z \
--slo-project=sample-project-name \
--slo-name=sample-slo-name
See the next section and the sloctl user guide for more information.
Published SLOs enable data-driven decision-making. Specifically, visibly exhausted or rapidly burning error budgets inform teams to take action, change course and prioritise reliability. The scale of the response and action can vary by the business risk involved. The SLO data should therefore help drive more informed decisions that are also less prone to influence from sources unrelated to reliability and business outcomes, such as organizational politics.
The SLODLC Implement Worksheet can guide teams through this phase.
Operate, iterate, and review
After implementation, teams can move to a run-and-maintain phase of operating SLOs as a routine part of everyday business. In this phase, teams will respond to error budget events and alerts. At the same time, the periodic review process will help refine and right-size the targets and alerts, feeding back into the design specification.
Tracking error budget compliance enables development teams to identify emerging issues and take corrective action before they escalate into problems. Similarly, alerts bring specific error budget events to engineers' attention. To minimise distraction and interruption, teams can use different alert thresholds and subsequent actions to ensure an appropriate escalation response at each threshold.
For example, an increasing level of response and escalation could result from breaching the 1-day, 7-day, 30-day, and 90-day error budgets, respectively.
Nobl9 allows alerting to many common platforms such as PagerDuty, Slack, and ServiceNow and makes defining alerts easy with templated alerting and reusable alert policies. As an example, the Nobl9 Alert Policy Wizard is shown below:
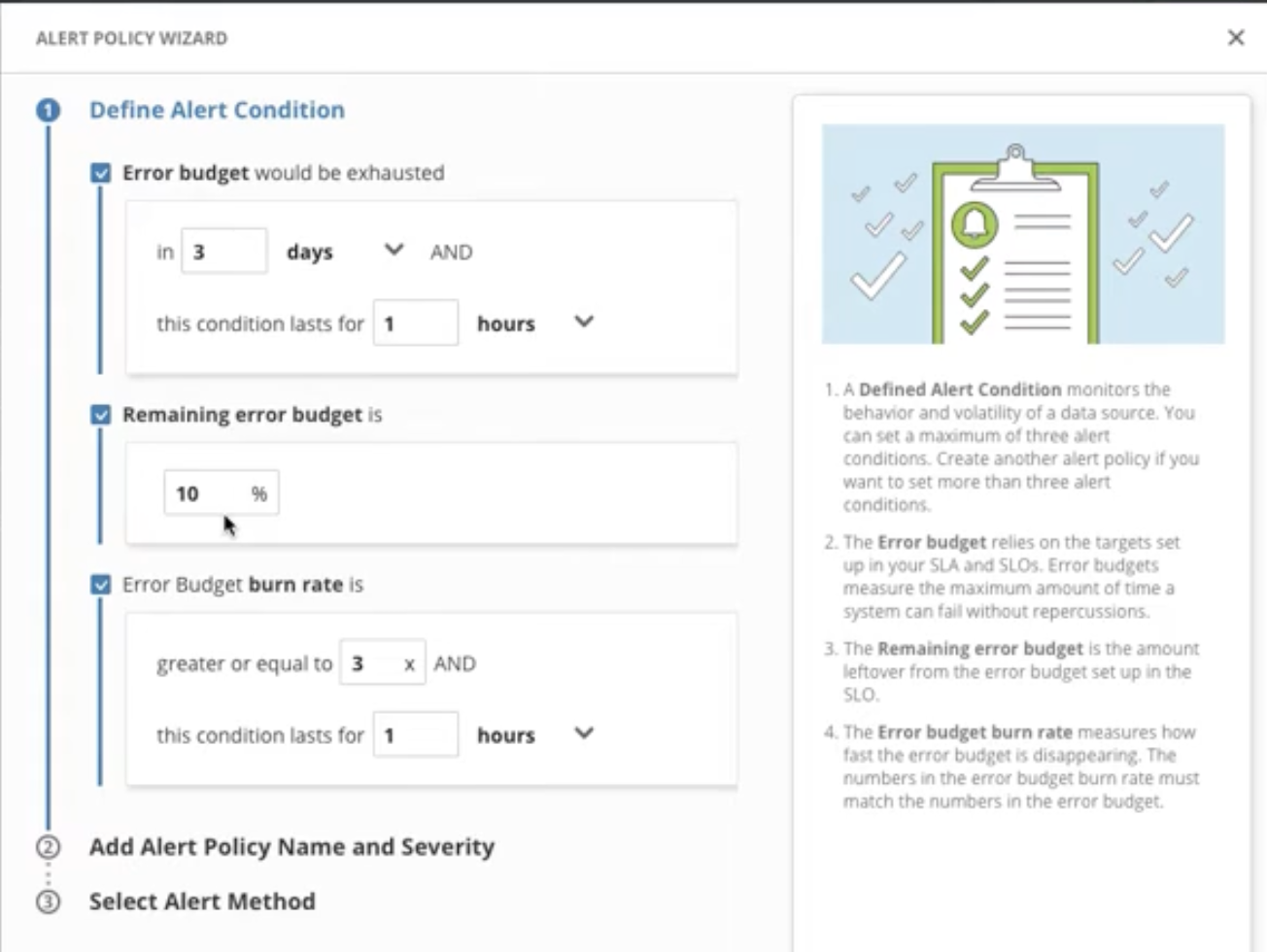
Organizations can use real-life operational data to validate their original SLI and SLO designs and refine them appropriately. This constant adjustment process should ensure that the SLOs remain meaningful to stakeholders and achievable for engineering teams.
SLO refinement and maintenance can then become an established part of your software development lifecycle, helping you “shift left” on your reliability engineering. This is made much easier by adopting tools that support SLOs-as-code. Nobl9 as mentioned earlier provides the sloctl CLI tool to generate SLOs as YAML definition files, CI/CD pipeline support via their GitHub Actions and GitLab CI integrations, and a Terraform provider to define and preserve SLO infrastructure as code in Terraform state. An example Terraform resource specification is shown below.
Composite SLO resource definition example in Terraform:
resource "nobl9_slo" "composite_slo" {
name = "${nobl9_project.this.name}-composite"
service = nobl9_service.this.name
budgeting_method = "Occurrences"
project = nobl9_project.this.name
# List the names of component SLOs your composite 2.0 must include
depends_on = [nobl9_slo.slo_1, nobl9_slo.slo_2]
time_window {
unit = "Day"
count = 3
is_rolling = true
}
objective {
display_name = "OK"
name = "tf-objective-1"
target = 0.8
composite {
max_delay = "45m"
components {
objectives {
composite_objective {
project = nobl9_slo.slo_1.project
slo = nobl9_slo.slo_1.name
objective = "tf-objective-1"
weight = 0.8
when_delayed = "CountAsGood"
}
composite_objective {
project = nobl9_slo.slo_2.project
slo = nobl9_slo.slo_2.name
objective = "tf-objective-1"
weight = 1.5
when_delayed = "Ignore"
}
}
}
}
}
}
As you gather more and more SLO data, you can further enrich your data analysis while benefiting from an increasing amount of historical data. You don’t have to wait for data to accumulate either. Nobl9, for example, has a Replay feature enabling you to collect SLI measurements from historical data for new and existing SLOs. The feature can be easily executed using Nobl9’s CLI, slotctl:
sloctl replay -p [project-name] --from=[YYYY-MM-DDThh:mm:ssZ] [slo-name]
This look-back data is then merged with your accruing real-time data, resulting in a much more comprehensive and accurate data set and corresponding error budget. This allows teams to define accurate prescriptive SLOs and SLIs in minutes.
Your ability to generate rich SLO data should allow for valuable data visualizations, pattern identification, and new business intelligence measures at product, financial, and leadership levels.
Applying continual improvement via regular reviews, as outlined in this SLODLC Periodic Review Checklist Example, helps normalize this operational phase into a routine part of high-quality service delivery.
Navigate Chapters: