
-1.png)

Table of Contents
Like this article?
Subscribe to our Linkedin Newsletter to receive more educational content
Subscribe nowCustomer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Integrate with your existing monitoring tools to create simple and composite SLOs

Rely on patented algorithms to calculate accurate and trustworthy SLOs

Fast forward historical data to define accurate SLOs and SLIs in minutes
What is Service Monitoring?
Service monitoring continuously observes systems to understand their performance and detect issues before users are affected. Modern monitoring extends beyond basic infrastructure metrics. It focuses on measuring and understanding the user experience. This is where SLO-based monitoring differs from traditional methods.
While older methods rely on technical thresholds (such as CPU > 80%), SLO-driven monitoring aligns metrics with the real user experience. Teams use a structured approach to achieve this which includes these three building blocks:
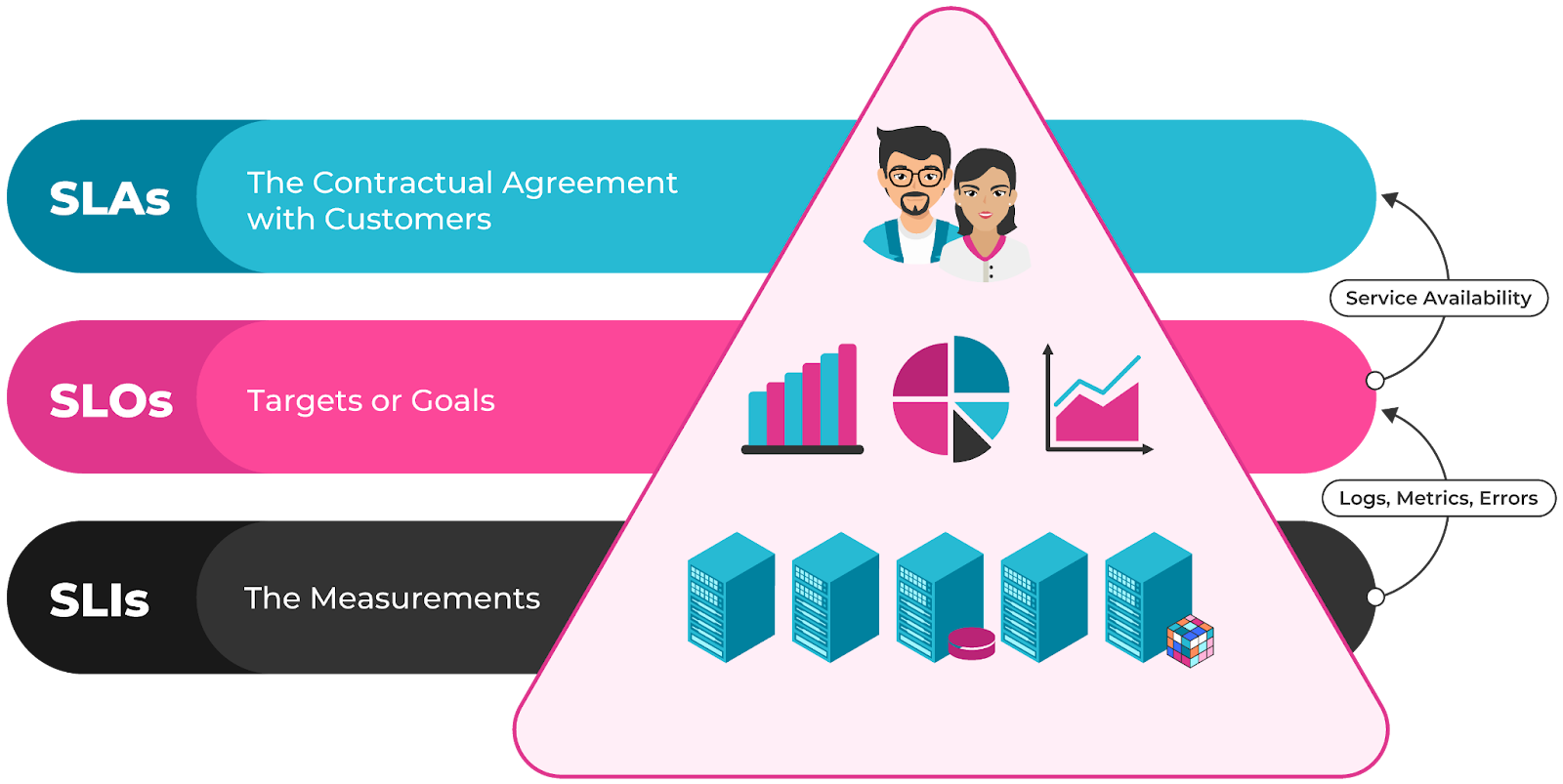
- Service level indicators (SLIs): Metrics that capture how your users experience the system.
- Service level objectives (SLOs): Performance targets or reliability goals tied to SLIs. For example, 99.9% of requests succeed over 30 days.
- Service level agreements (SLAs): Formal commitments to customers backed by internal SLOs, often tied to penalties for failure.
Customer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
SLODLC Discovery Phase: Observe system behavior
The first phase of the SLODLC framework is about understanding your system before making monitoring decisions.
Understand system and user flows
Effective monitoring starts with clearly understanding how your system works and its user interaction. This foundational step helps ensure that monitoring efforts are aligned across user actions and how those requests travel through the system. The SLODLC Discovery Worksheet is an excellent tool for achieving this and offers a structured way to document critical services, user flows, failure modes, outage analysis, and telemetry mapping. Teams use it to map out the most essential parts of the application, like login flows, dashboards, and billing systems, as these are typically the highest-impact services for end users.
As the SLODLC handbook advises, "Start with something meaningful and visible to users, but simple to define". This means engaging with product and engineering teams to surface the most valuable user journeys, like onboarding, payment submission, or file upload, and identifying the systems and dependencies that power them.
These early conversations also help uncover known failure points or recurring incidents. They also help review past incidents to understand where telemetry was lacking, which signals were most useful in diagnosis, and where new monitoring coverage may be needed.
For example, a SaaS platform's user experience often hinges on login, dashboard, and billing services. These flows are apparent, and their performance directly affects satisfaction and trust.
Choose what to monitor
Effective observability requires a move from speculative monitoring (choosing metrics based on assumptions or hunches) to evidence-driven decisions rooted in real system behavior. This means learning from the past to shape what needs to be tracked going forward. Instead of guessing which metrics might be necessary, base your monitoring on actual incidents, user pain points, and observed gaps in telemetry.
Review past outages and incidents, ideally from the last 6 to 12 months. What degraded? What failed? What were the early warning signs, and where were they missing? These retrospectives help pinpoint which metrics or events were useful or considerably absent when troubleshooting. The outage analysis section of the SLODLC Discovery Worksheet offers a practical format to capture this analysis.
This exercise often reveals patterns such as telemetry that existed but didn’t trigger alerts, alert fatigue from noisy thresholds, or missing instrumentation altogether. For example, a team might discover that latency metrics were available but not granular enough to detect regional slowdowns, or that logs existed but weren't structured for alerting. These lessons directly inform better monitoring design.
By basing your monitoring on observed system behavior, you can enhance signal quality and minimize noise, particularly in alerting. This phase also helps identify early candidates for SLIs. When chosen wisely, these SLIs become the foundation of your SLOs, enabling structured reliability goals and more innovative alerting practices. So, take the time to analyze your system’s behavior.
Select data sources
Here, you determine the sources of your monitoring data. The quality of your SLIs and the overall effectiveness of your monitoring depend on choosing reliable, relevant telemetry. Without trustworthy data, observability efforts risk becoming speculative. Data can come from one or many sources and typically fall into one of three types: metrics, logs, or traces. Choosing and integrating these telemetry sources during the observation phase ensures that future SLIs, SLOs, and error budgets are based on data reflecting system behavior. The SLODLC Discovery Worksheet provides a structured way to perform this analysis.
Each has strengths and limitations. Together they provide a collective picture of system behavior and lay the foundation for service monitoring initiatives.
Metrics
Metrics are quantitative, structured, timed measurements typically collected from monitoring systems. They are the foundation of most SLIs because they are efficient, lightweight, and easy to aggregate. Metrics help quantify aspects of system performance such as availability, latency, throughput, and error rates.
For example, a metric like http_request_duration_seconds_bucket from Prometheus enables teams to monitor the duration of requests broken down into latency buckets. This is a powerful way to track performance thresholds and align them with user expectations. Moreover, metrics can be processed in real time, supporting proactive alerting and fine-tuned error budgeting. Their structured nature makes them ideal for building high-resolution dashboards and automated health checks.
Modern observability platforms such as Nobl9 allow teams to integrate with these data sources and apply "good" vs "total" query logic, also called ratio metrics, to define SLIs, which then support the reliability targets set by SLOs. For example, here is how such an SLI may be defined:
- Tool: Prometheus
- SLI calculation: SLI = good_events / total_events
- Example metric: http_request_duration_seconds_bucket tracks request latency distribution across pre-defined time buckets
- Example SLI: Percentage of successful login requests under 500ms
These metrics often serve as the starting point for tracking system user-perceived reliability and are directly supported by the SLODLC Implementation Worksheet in the collecting SLI section.
Logs
Logs provide unstructured, event-level details that capture what happened at specific moments within the system. These logs are crucial in auditing events, especially failures, by surfacing the exact conditions under which an issue occurred. A typical log entry looks like this:
{
"event": "payment_failed",
"code": "timeout"
}
This indicates that a payment failed and provides the reason for the failure (in this case, due to a timeout).
While logs are not typically used as primary sources for defining SLIs due to their freeform nature, they play a vital supportive role. During the Observing System Behavior phase of the SLODLC framework, logs help identify gaps in existing telemetry, validate helpful information during past incidents, and inform the development of new SLIs by illustrating real-world failure scenarios.
The SLODLC Discovery Worksheet provides a great reference to document which logs were useful during past incidents, which were missing, and how they might contribute to more effective monitoring going forward.
Traces
Traces show the journey of a request that flows through multiple services, capturing timings and dependencies across service boundaries. Traces are essential for understanding latency, bottlenecks, and service-to-service interactions. They help define more sophisticated SLIs related to distributed performance.
Traces are necessary during the "Observe System Behavior" phase of the SLODLC process because they reveal how real requests behave under normal and failure conditions. Traces also support the identification of timing thresholds, service dependencies, and request propagation paths, helping teams pinpoint exactly where slowdowns or errors occur.
For example, consider a trace showing the span from checkout → payment gateway, → database write like in the image below.
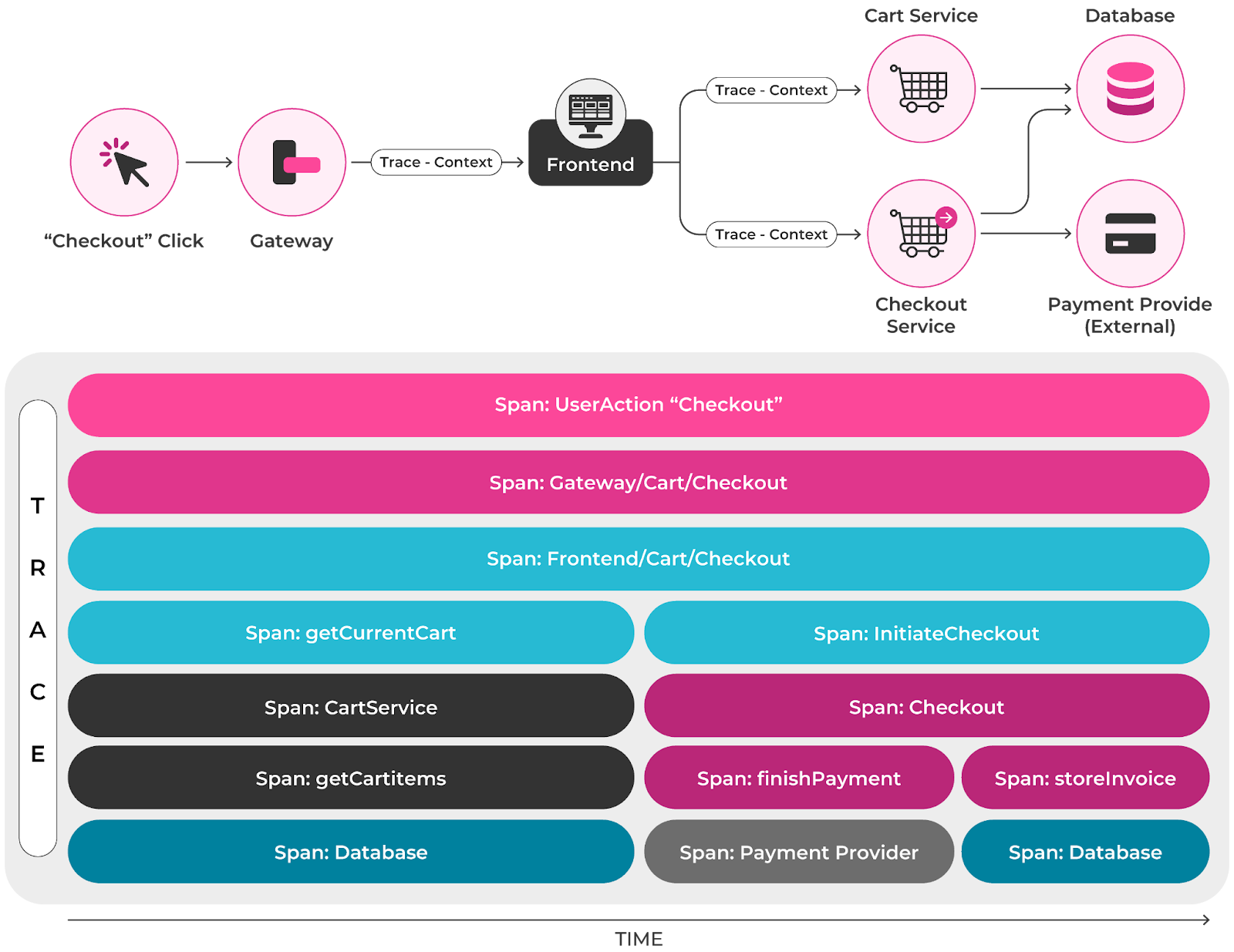
This may reveal a consistent delay in the payment gateway step, leading to the definition of a latency-based SLI focused on that service.
SLODLC Implementation Phase: Implementing monitoring
The next phase of the SLODLC is the implementation phase. In this phase, teams implement the SLIs, SLOs, and monitoring policies that enable effective service monitoring.
Define and collect measurable SLIs
Once the right data sources are identified, the next step is to define SLIs. These core metrics reflect how well your service is performing from a user's perspective. This foundational concept in modern SLO-driven reliability practices aligns with widely adopted observability methodologies.
SLIs are not arbitrary. They’re precise, meaningful metrics based on user-impacting events. They help answer how reliable this service is for users. And how do you measure that reliability consistently? A good SLI uses structured telemetry to measure the success of a user journey. Nobl9 recommends calculating SLIs using the formula:
SLI = total_good_events / total_events
This ratio tells you how often the system behaved in a way that users would consider successful over time. For example, your service processed 10,000 HTTP requests in a 5-minute window, and 9,980 returned a 200 OK. Your SLI would be:
SLI = 9980 / 10000 = 99.8%
SLO Management tools make this process easier by integrating with existing telemetry. Your teams can define SLIs using queries directly from their existing metrics.
A simple how-to approach for defining SLIs is:
- Start with a real user journey – Choose a high-impact and measurable experience, like checkout success, dashboard load time, or file uploads.
- Choose a data source – Use telemetry systems already in place.
- Define good and total events – Use an SLI builder to input queries for "good" and "total" conditions.
- Preview and validate – Review historical data and ensure the SLI aligns with actual service behavior.
- Focus on what users care about – Prioritize signals that reflect real-world experience, not just internal system metrics.
This approach ensures that SLIs are technically feasible and use measurable, relevant data. The SLODLC Implementation Worksheet—Section 2: Collect SLIs provides a space to document how each SLI is calculated and which data source supports it.
Set meaningful SLOs
After clearly defining and validating SLIs, the next step is to establish SLOs. These performance goals indicate the level of reliability a service must maintain over time. SLOs help teams shift from observing system behavior to setting user-centric reliability targets. Reliability targets based on SLOs are a key pillar of modern SRE practices, enabling more predictable service performance, informed trade-offs, and reduced operational noise. Defining a meaningful SLO requires close collaboration between engineering and product stakeholders. Together, teams must determine what “good enough” looks like for the user.
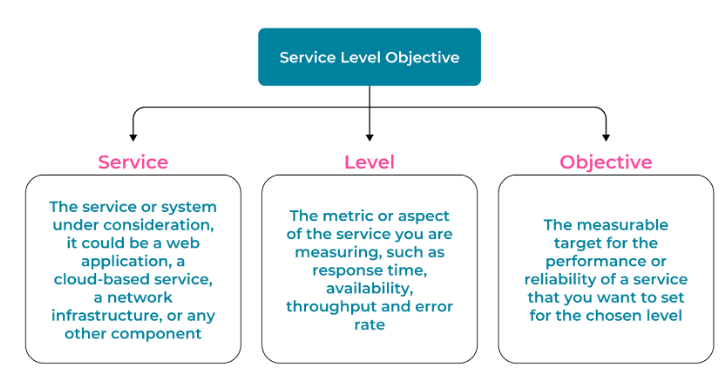
An overview of the three components of an SLO. (Source)
A good practice is defining baseline targets (conservative, realistic thresholds based on historical data) and aspirational goals (targets that reflect continuous improvement). This dual-target model helps teams remain grounded while aiming higher over time.
For more complex services, composite SLOs can combine multiple SLIs, such as availability and latency, into a single objective. These composite objectives offer a holistic view of service health across critical user journeys, making them especially valuable in distributed systems where reliability depends on several interconnected components. More information can be found on our Composite Guide.
The SLODLC Implementation Worksheet prompts teams to document these goals in a structured format, ensuring each SLO is clear, measurable, and technically feasible to track.
Track and enforce error budgets
It is crucial to clearly communicate the potential unreliability of a service before action is required. Error budgets quantify the permissible level of service failure within a defined period. An error budget is calculated as the inverse of an SLO.
Error Budget (%) = 100% - SLO Target (%)
For instance, if an SLO defines 99.9% availability over 30 days, the corresponding error budget is 0.1%, translating to roughly 43 minutes of allowable downtime.
100% - 99.9% = 0.1%
This budget provides a clear boundary as long as your team stays within it. As the error budget is gradually consumed, teams typically slow their release cadence, introduce more stringent testing, or prioritize fixes over features. Importantly, not all releases are equal. Suppose a feature is business-critical or resolves an ongoing user issue. It may proceed even when the error budget is nearly exhausted, provided an acceptable mitigation plan or rollback strategy is in place. This flexible approach acknowledges that reliability is not about avoiding failure at all costs, but about making informed trade-offs.
Reliability platforms such as Nobl9 support SLO-driven practices and help continuously track how much of the error budget has been consumed. These tools offer real-time visualizations, show burn rate trends, and correlate service events to budget consumption, providing actionable insight into reliability risk. Alerting systems can also be configured to trigger responses as burn rates accelerate, making the concept of error budgets not only measurable but enforceable. Error budget policies ensure team consistency and align reliability enforcement with user priorities.
An example of an error budget policy table is:
|
Policy Trigger |
Recommended Action |
|
30% of the budget was used in 6 hours |
Slow non-critical rollouts, review telemetry, and validate alert sensitivity |
|
50% of the budget was burned in 1 day |
Escalate for team review, consider pausing lower-priority releases, and open a post-mortem |
|
75% of the budget was used within 1 week |
Require engineering and product alignment before new deploys |
|
100% budget exhausted |
Freeze regular deployments, allow critical or mitigated releases with approval |
|
High-priority feature during high burn |
Allow conditional release if the benefit outweighs the risk and mitigations are in place |
|
3 consecutive breaches in 3 months |
Reassess SLO targets, consider architectural changes, or improved instrumentation. |
These policies are typically enforced through a combination of automation and team processes such as:
- Real-time dashboards to monitor budget usage and trends
- Alerts based on burn rate thresholds or consumption percentages
- Integrations with platforms like Slack, PagerDuty, Jenkins, or GitHub Actions to trigger actions or enforce deployment
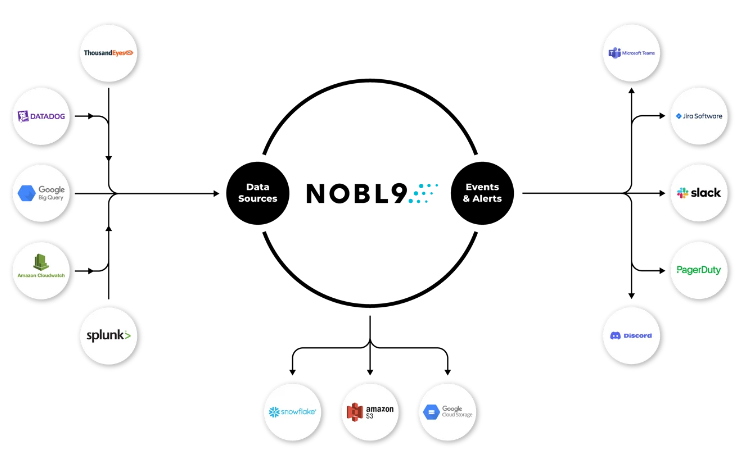
An example flow of data sources, events and alerts, and storage locations for the Nobl9 platform. (Source)
Alerting tools and policies for effective service monitoring
Modern service management requires alerting and policy enforcement that can keep up with the complexities of modern systems.
Move beyond static thresholds
Traditional monitoring often relies on static thresholds like “CPU > 80%” or “memory usage > 75%.” While these alerts are easy to configure, they frequently occur. They’re either too noisy and get triggered when there's no noticeable service degradation or too narrow, missing meaningful incidents. This leads to false positives, alert fatigue, and a response to infrastructure anomalies that don't affect customers. In dynamic and distributed systems, this approach can create more confusion than clarity.
Instead of focusing solely on infrastructure health, SLO-based alerts are tied to user-perceived reliability. For example, rather than alerting on CPU usage, an SLO-based alert might be triggered if 1% of user requests fail within the window, something that truly reflects degraded service. This alerting model ensures your team responds to actual reliability risks without being overwhelmed by noise.
Alert on budget burn rate
Alert fatigue is a common pain point in traditional monitoring setups. Teams often receive alerts triggered by technical anomalies, which may not reflect service degradation or user impact. The result? Missed incidents, delayed responses, and overburdened on-call engineers.
To combat this, modern SLO-based alerting has the concept of burn rate. It is the speed at which your error budget is being consumed. Burn rate-based alerts help shift attention from raw infrastructure metrics to user-centric reliability risks. Instead of triggering on static conditions, alerts are based on how quickly a service violates its defined SLOs.
Burn rate alerts are particularly effective because they’re time-aware. They consider both the severity and speed of the problem. A short, sharp spike monitoring and burn alert, even if your overall uptime still appears acceptable, enables faster, more meaningful responses to issues that matter.
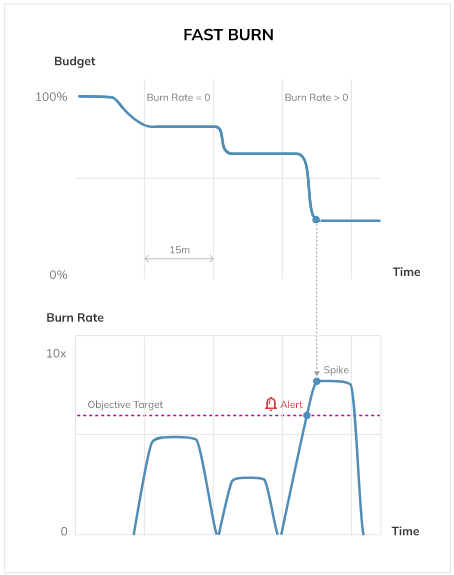
Example error budget burn rate visualizations in Nobl9. (Source)
Define escalation policies
The heart of any reliable system is monitoring and knowing who should act when things go wrong and how quickly. Escalation policies bridge the gap between alerting and response, ensuring that the right people are notified through the proper channels and have the correct severity level when SLO breaches occur.
Unlike traditional threshold-based alerts that can flood your team with low-severity noise, modern SLO-based monitoring systems enable intelligent, automated escalation. When a service starts consuming its error budget too quickly or breaches an SLO, there is a clear, predefined path for notification and response.
One of the most essential elements of this strategy is integration with incident response tools. When an SLO-based alert is triggered, it can automatically notify the appropriate responder. These integrations ensure that alerts don't just end up as unread emails; they drive action.
Moreover, escalations can be severity-based. For example, if 10% of your monthly error budget is consumed in an hour, the system might send a low-priority message to Slack. But if 50% is burned in the same window, it could escalate with an immediate page to your on-call engineer. This flexibility helps teams prioritize more effectively and respond with the right urgency. Organizations shift from reacting to infrastructure noise to responding based on actual business impact by tying escalation policies directly to service-level indicators and objectives. A quality escalation policy enhances operational efficiency and fosters customer trust by reducing the time it takes to identify and resolve significant service degradation.
Visualization and operational dashboards for service monitoring
Visualization helps teams have laser focus on what matters and enables simplified stakeholder communication. The service monitoring best practices in this section can help teams implement dashboards and visualizations that complement and improve their overall service monitoring program.
Build dashboards
Monitoring is only effective when its insights are visible, actionable, and shared across teams. Dashboards are the interface between raw telemetry and operational awareness. They transform service health data into real-time visibility for engineers, product owners, and executives.
At a minimum, a service reliability dashboard should include:
- Key SLIs like request latency, error rates, and availability
- SLO compliance status to determine how well each service is tracking against its objectives
- Error budget trends that indicate how much budget remains, and how fast it’s burning
These elements can help your team assess current performance at a glance and quickly identify where attention is needed. Modern platforms like Nobl9 offer native dashboarding capabilities that automatically visualize these indicators, often without requiring in-depth configuration or scripting. Another powerful feature is the ability to create SLO roll-ups. A single dashboard component that aggregates multiple individual SLOs into a holistic, service-level view.
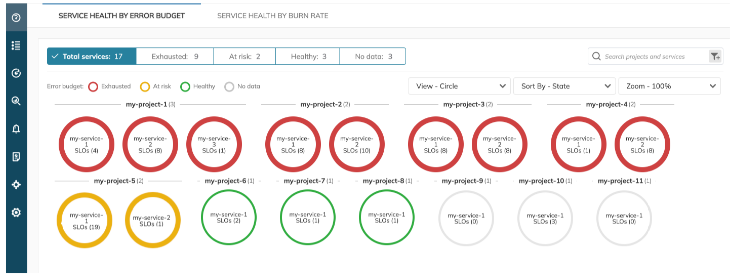
An SLO dashboard for service monitoring in Noble9. (Source)
Dashboards also serve an essential cross-functional role. In many organizations, reliability is not just an engineering concern; it’s a business priority. That’s why these platforms offer executive-friendly dashboards, designed to summarize reliability posture in a way that’s easy for stakeholders to interpret. These views highlight compliance trends, recent incidents, and risk areas without diving into technical complexity.
Weekly reliability reviews
Service monitoring is not just about collecting data; it’s about using that data to improve the system. One of the most effective ways to make reliability actionable is to establish a regular flow of weekly reliability reviews. These reviews bring teams together to evaluate how services are performing against their defined SLOs and to decide what, if anything, needs to change. The primary purpose of these meetings is accountability. By regularly reviewing SLO compliance, error budget usage, and recent service behavior, your teams can stay aligned with their reliability goals and maintain a shared understanding of what is working and what is not.
A typical review might include:
- Error budget usage – How much has been consumed, and at what rate?
- SLO compliance – Are services meeting their objectives?
- Recent incidents or anomalies – What triggered budget burn, and what were the root causes?
- SLI changes – Have definitions changed? Are there gaps in telemetry?
Modern service monitoring tools make this process much easier by providing shareable, visual, and up-to-date dashboards and reports. Instead of digging through logs or spreadsheets, teams can walk through intuitive visuals highlighting key trends and areas of concern. These tools often allow you to drill down into individual services, compare performance across teams, and flag specific issues for follow-up.
Navigate Chapters: