
-1.png)


TL;DR—To avoid scalability cliffs, you should pay attention to creeping latency. Think of it like a tire. If you have low pressure, you had better keep an eye on it to avoid a catastrophic blow out.
Knative’s open source framework is useful in providing a serverless-like experience on top of Kubernetes, including features like an automatic scale-to-zero function. I had a conversation with Matt Moore, a software engineer on the Knative Project at VMware, to dig deeper into how he uses latency metrics to observe cold start times from scale-to-zero, what he discovered in the scale testing process, and how he arrived at the not-so-obvious solution.
Matt began with a test of 1,000 services. As shown below, the more services that were deployed, the longer it took for those services to become ready, increasing linearly. In addition to the time for initial deployment, cold start latency was also trending upwards and lagging, with an overall jump from ~2 to ~12 seconds.
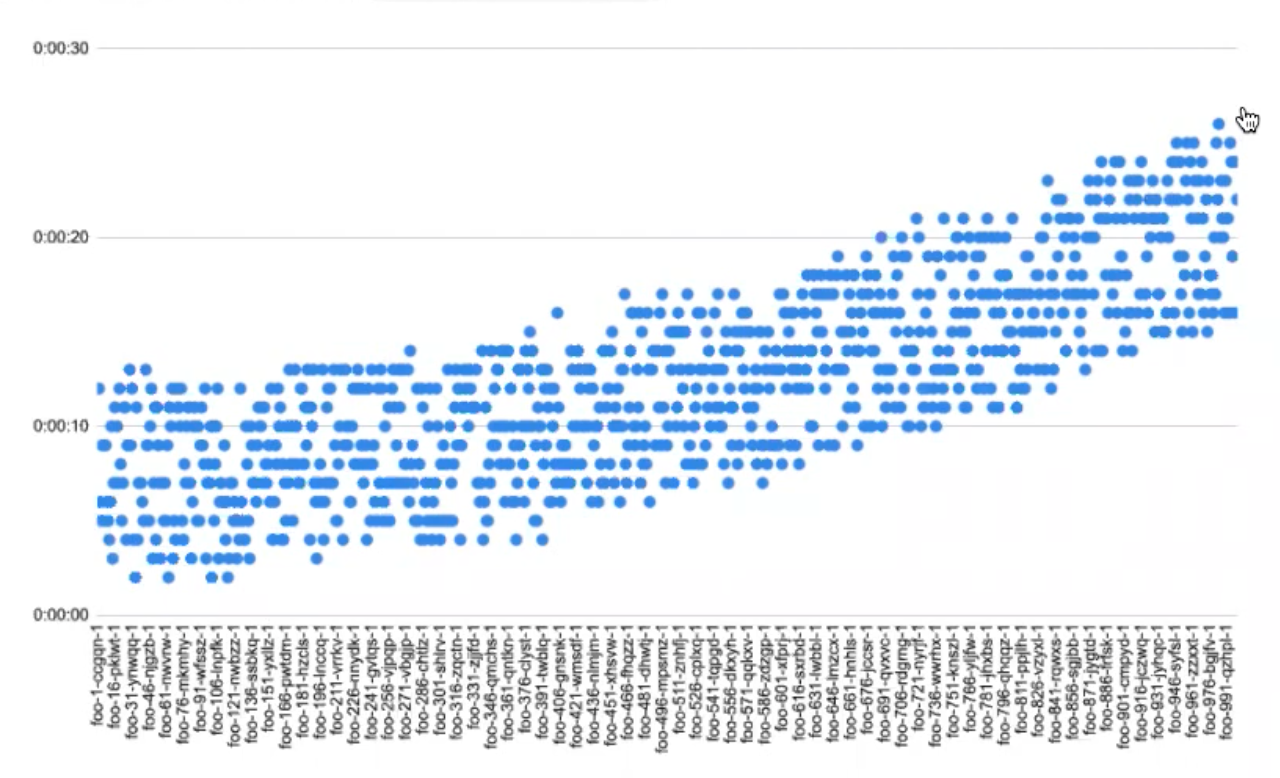
Sometimes it’s worth spending the time to push things to a certain scale and see them fail.
After this test, Matt had an unusual suspicion that maybe the trend had to with service links. He had just had a conversation about the topic earlier that week, so it was fresh on his mind. He was aware that service links stick environment variables into your container for every service in your namespace. So, with each additional Kubernetes service you have, your environment grows a lot. Eventually, it takes a ridiculous amount of time to start up your pod.
So as a sort of “educated guess,” he decided to disable the injection of service links. He re-ran the same 1,000-service experiment (shown below), and everything was noticeably and consistently faster. Cold start latency also improved.
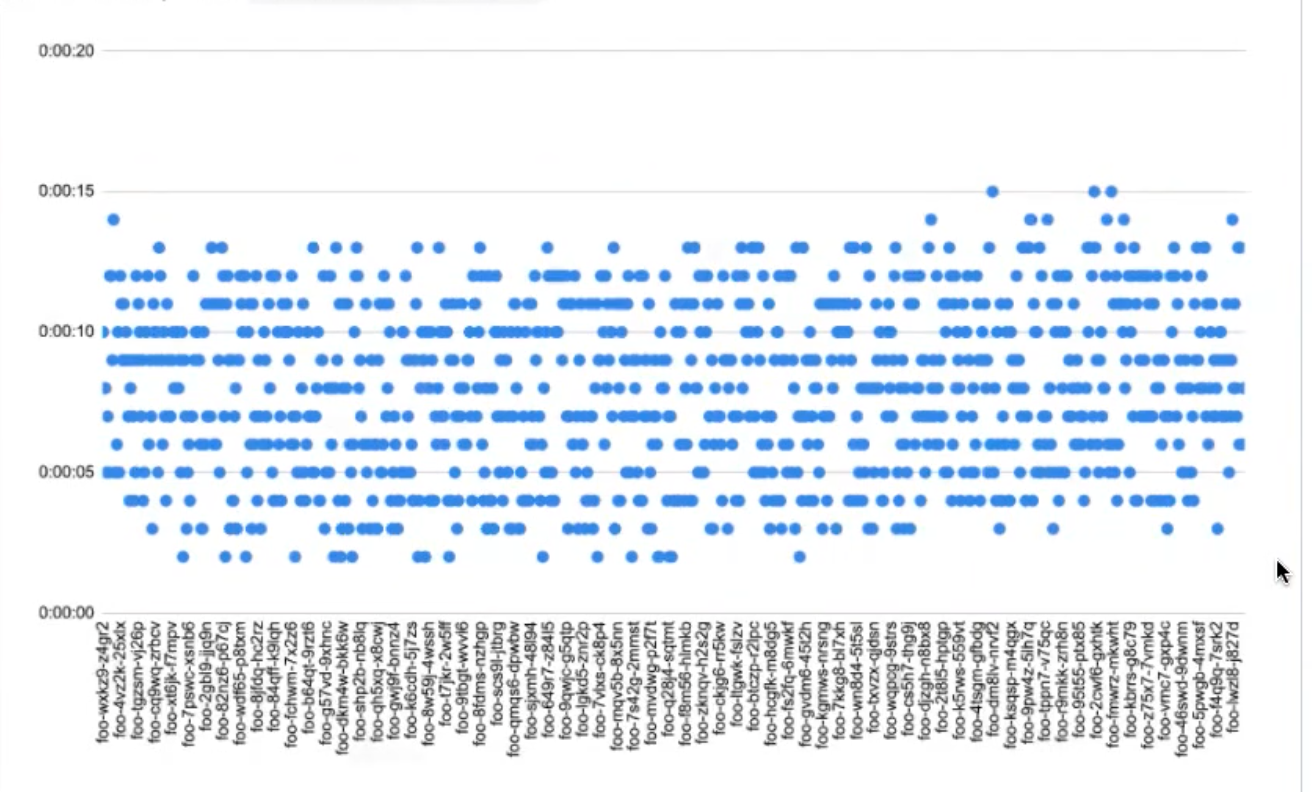
Matt walked me through the series of clues that lead him to this hypothesis:
- Before performing this controlled experiment, Matt’s very first test included a total of 1,500 services, with a loop that added a new service every 10 seconds. He noticed that an interesting cliff showed up once he hit 1,200 services, where the environment grew so large that the container startup processes were failing completely. Not only could he no longer deploy a new service, he couldn’t even start up pods with existing services that had been scaled to zero.
- By creating a Knative service in another namespace, Matt observed a different trend entirely. The deployment latency for this service was surprisingly short, and the previous issue of exaggerated cold start latency or even failure to cold start at all wasn’t there. That told him that the issue had nothing to do with the number of services in general; rather, it was something specific to how services in that namespace were being started.
- Finally, Matt can attribute part of his discovery to the fortunate coincidence of having just talked about service links in a conversation earlier that week. With the quick change of turning off the default service links, the problem that once had the potential to be detrimental was fixed.
All in all, Matt’s advice is that “Sometimes it’s worth spending the time to push things to a certain scale and see them fail. Before this, I had never seen a process fail to start up because the environment had grown too large—it simply hadn’t occurred to me until I began debugging this. All it took was a discussion about how Kubernetes was stuffing all this junk into my environment to prompt us to disable it.”
There are many factors that may contribute to slow growth—like adding features, image size, or loading more information at startup. Because of this, it’s easy to discount observed growth as normal and natural. But because there are situations like Matt’s where unexpected failure can lead to disaster, it’s critical that you understand the reasons behind certain behaviors like growing environments. Read more about Matt’s testing process and results here.
Image Credit: Gustavo Campos on Unsplash
Share:







Do you want to add something? Leave a comment