
-1.png)


Originally Published at Supertenant.com on June 20th, 2023
A Tale of Frequent Flyers and Baggage Delays
As a seasoned traveler, you've mastered the art of packing. Your multiple checked bags hold everything from your cherished pillow to essential sports equipment. You've chosen an airline, lured by their promise of having all checked luggage ready for pickup within 20 minutes post-landing. It sounds perfect for your fast-paced travel itinerary.
However, reality doesn't always match the promise. Despite the airline's pledge, you're often left waiting well beyond the 20-minute window. Your multitude of bags seems to slow down the system, making you a regular fixture at the carousel while others whisk their luggage away. The airline, while upholding its service level on average, fails to meet your individual needs, leading to consistent, frustrating delays. But what if there was a way to mitigate these burdensome delays?
The Necessity for Customer-Focused Observability
Much like the airline scenario, cloud-based software services catering to a multitude of customers (tenants) often set application-level service level objectives, or SLOs. For instance, they might promise "99.999% uptime and requests completed within a 1-second timeout, excluding downtime," similarly to how the airline promised your luggage within 20 minutes of arrival.
On the surface, the service appears to be performing commendably, adhering to its uptime commitment. But here's where the problem lies – these aggregate metrics can often obscure individual tenant experiences.

Think of a tenant who frequently experiences long latency or unexpected downtime due to their unique usage pattern. This is much like our frequent traveler with multiple bags. These issues don't reflect in the overall 99.999% uptime metric, rendering their specific dowtime virtually invisible.
This lack of individualized observability can lead to overlooked opportunities for service improvement and resource optimization, ultimately resulting in diminished customer satisfaction and churn.
SuperTenant and Nobl9 Collaboration
We're excited to shed light on a collaborative effort between SuperTenant and Nobl9 that is set to transform the way SaaS vendors can utilize SLOs, by introducing a tenant-centric SLO tracking capability.
SuperTenant is a transformative no-code platform that brings unparalleled visibility and contention remediation to multi-tenant infrastructures. Our unique offering allows for precise tenant performance and cost observability as well as Quality of Service (QoS) for each tenant in a shared infrastructure.
If you aren’t familiar with Nobl9, it’s a purpose-built SLO platform that lets you define SLOs-as-code, collect data from many sources, report on it, and importantly proactively trigger various events from warnings to automation to pages based on SLOs-at-risk. As part of our collaboration with Nobl9, we're surfacing the tenant centric approach within the Nobl9 platform, expanding on a holistic service level view for the organization.
SuperTenant's unique offering enables us to address this challenge head-on, providing observability both at the micro-service level and for each individual tenant within a shared micro-service.
Customer Level Observability in SuperTenant
The SuperTenant UI provides detailed performance metrics for micro-services and infrastructure layers collectively named ‘Resources’.
In the screenshot below we see a latency view on an HTTP service. The resource average latency fluctuates, but does not cross 73ms.
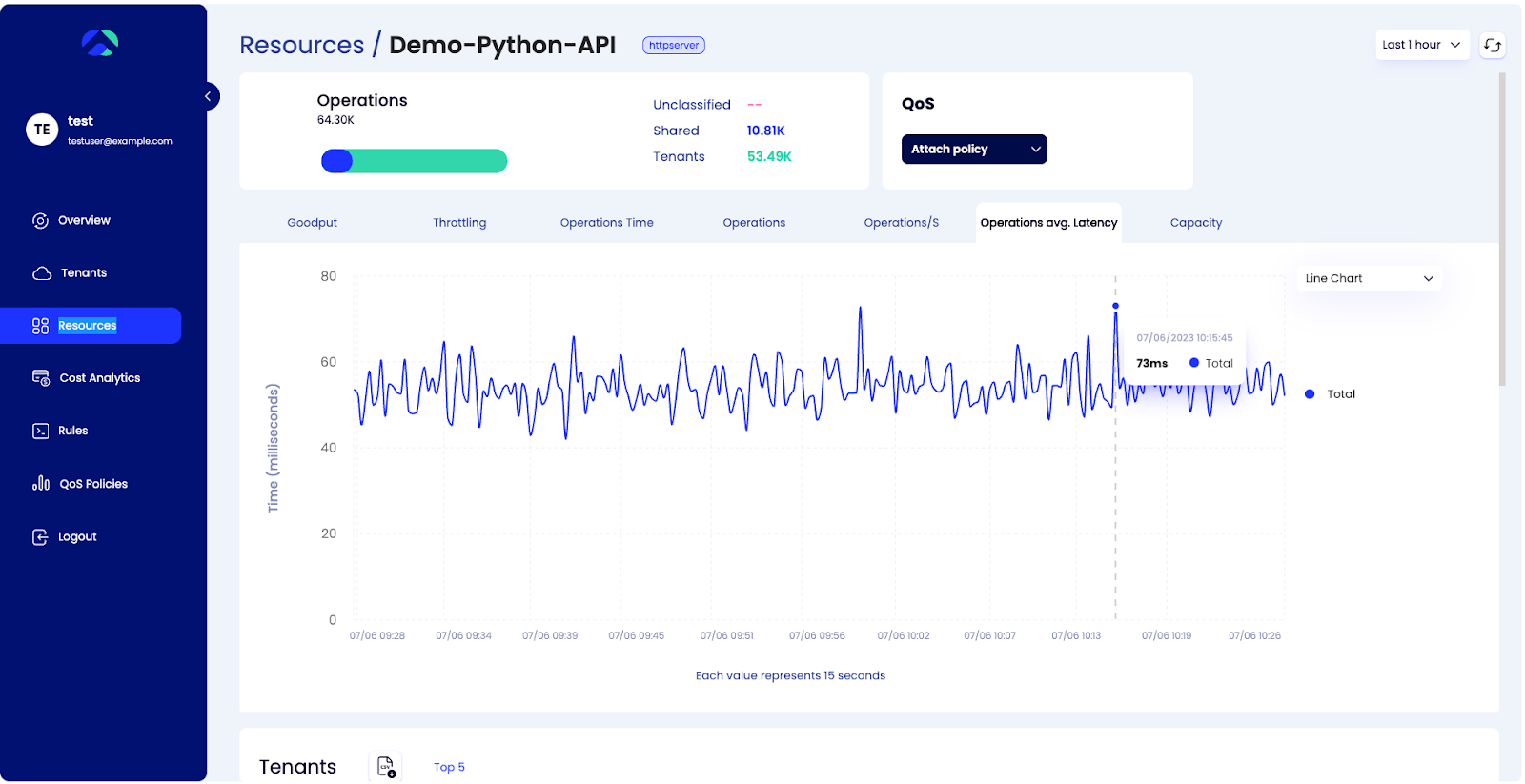
With SuperTenant, you can see performance metrics at the tenant level, which provide unique insights into how individual customers experience your application.
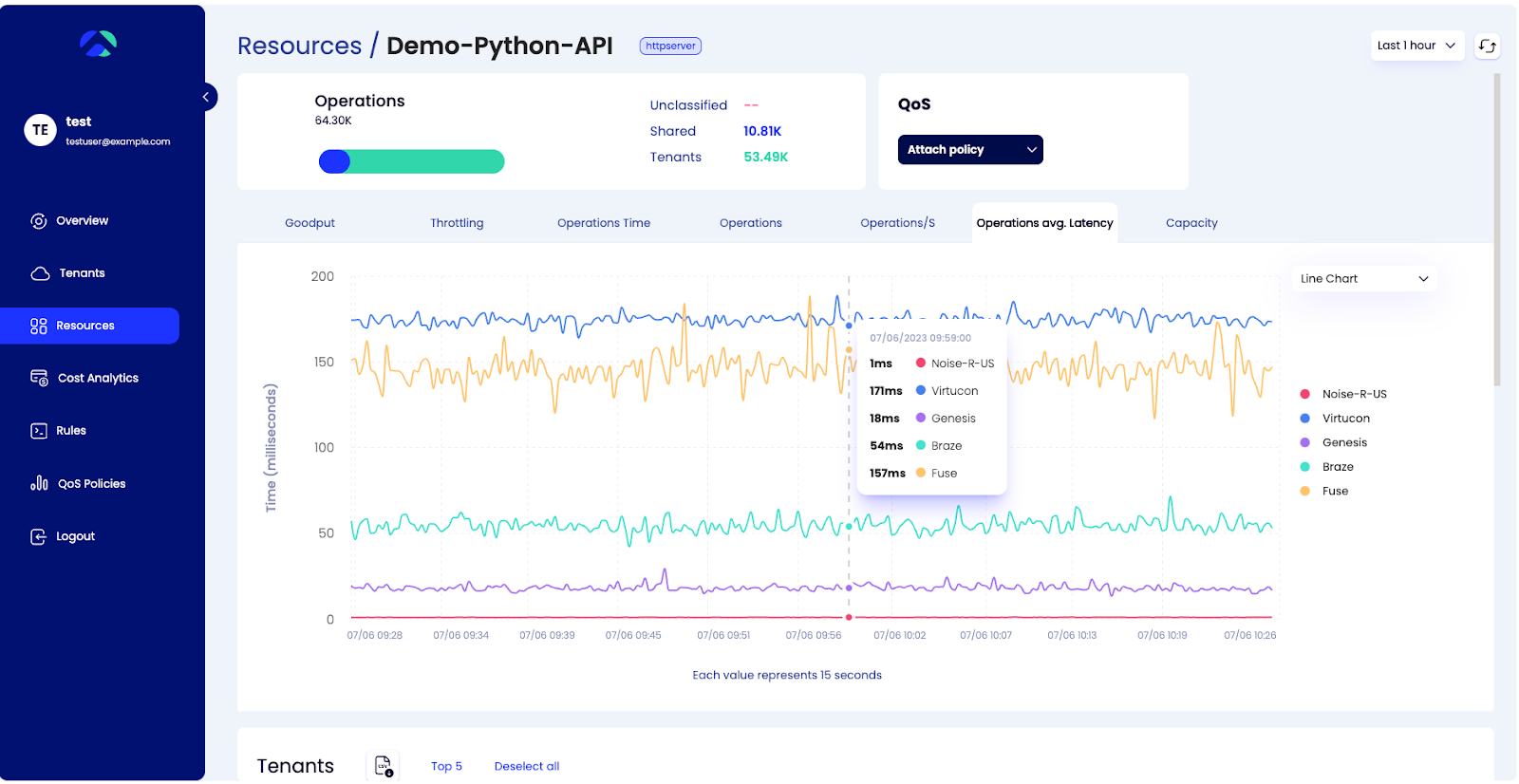
Below we see the Top 5 tenants with the highest average latency. This view uncovers the fact that we have two tenants with 2.5x higher average latencies for all their operations on this HTTP resource.
The performance and experience of these customers – Virtucon and Fuse – would be much worse than that of a typical customer.
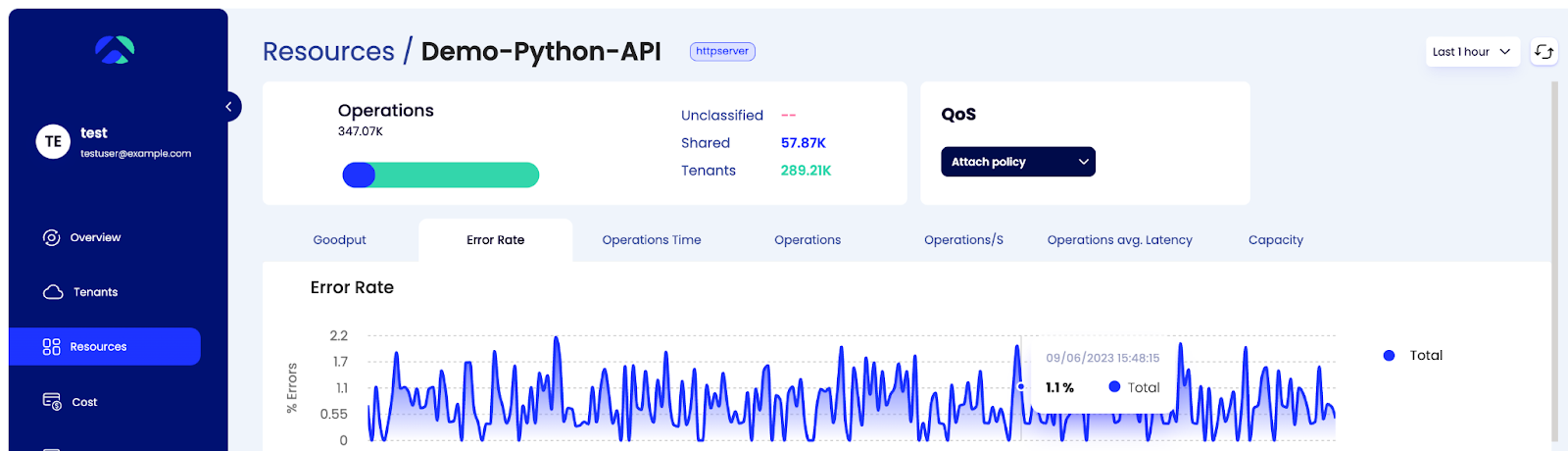
We can see a similar pattern with metrics tracking errors. On the service level as a whole the error rate fluctuates, but does not cross 2.5%.
Yet when we look deeper, we see that some tenants are experiencing as high as 5.9% of their operations completing in an error.
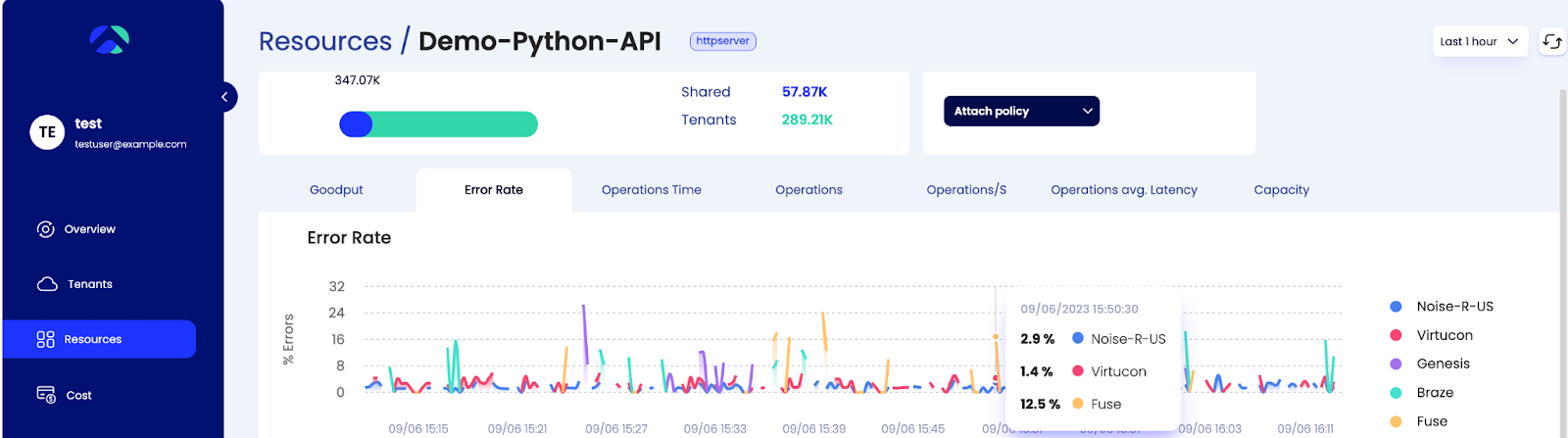
These major blind spots in our customers' experiences would remain hidden with traditional observability solutions, typically surfacing either through support cases or, even worse, as churn.
So, how do we monitor and address customer-specific performance degradations before it escalates? The answer lies in defining and monitoring SLOs, not just at the service-level, but at the tenant-level too.
This is where the SuperTenant and Nobl9 integration comes into play.
Tenant Level SLO Tracking in Nobl9
The integration between SuperTenant and Nobl9 is achieved with the help of Prometheus serving as middleware. SuperTenant exposes tenant-centric metrics and tenant-SLO metrics, whileNobl9 periodically queries Prometheus and exposes this data as SLOs in the Nobl9 platform.
Below is an example of such an integration which highlights the typical blind spots when not monitoring tenant-level SLOs.

In the Nobl9 UI we’ve defined two sets of SLOs with the goal of tracking the health and performance of our HTTP service both on the service level as well as tracking health and performance on a tenant basis.
In our organization we define healthy service state as follows:
- Service average latency < 100ms
- Service Error rate (percentage of operations ending in error) < 1%
- Service total error count < 20 (15 seconds window)
We also want define performance and health objectives at the tenant level as follows:
- Less than 3 tenants has average latency ≥ 100ms
- No tenants with more than 3 errors (15 seconds window)
- No tenants with Error rate > 1%
Looking at a glance, the SLOs are met at the service level, and the observed latency, error count, and error rate are within the defined objectives.
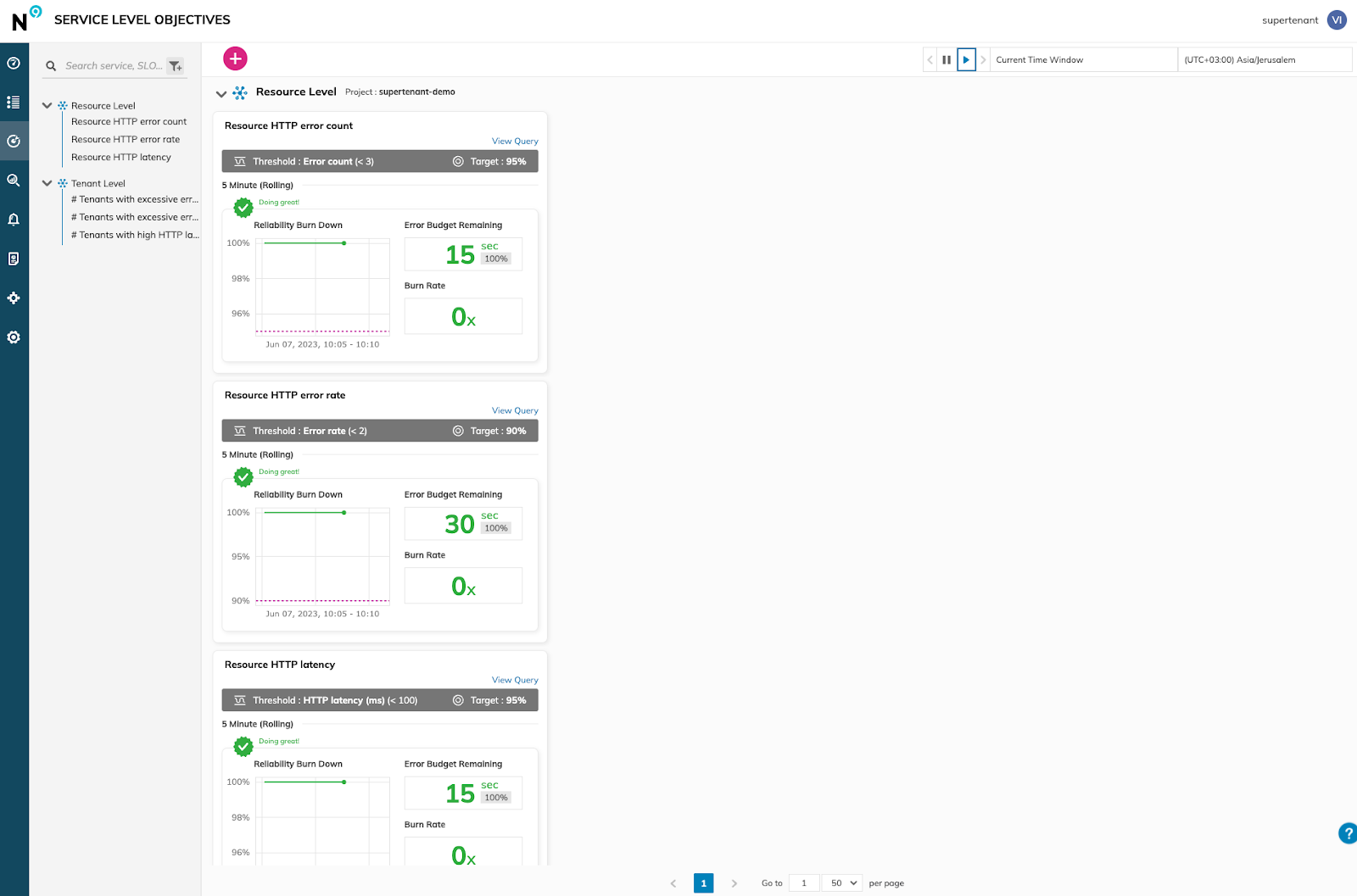
Yet looking at the tenant specific SLOs, we’re seeing a lack of adherence to 3 SLOs we defined.
This is no surprise as we’ve already seen this in the SuperTenant UI – namely we saw that some tenants are experiencing the majority of the errors of the service and others have average latency that is 2.5x higher than the average latency of the whole service.
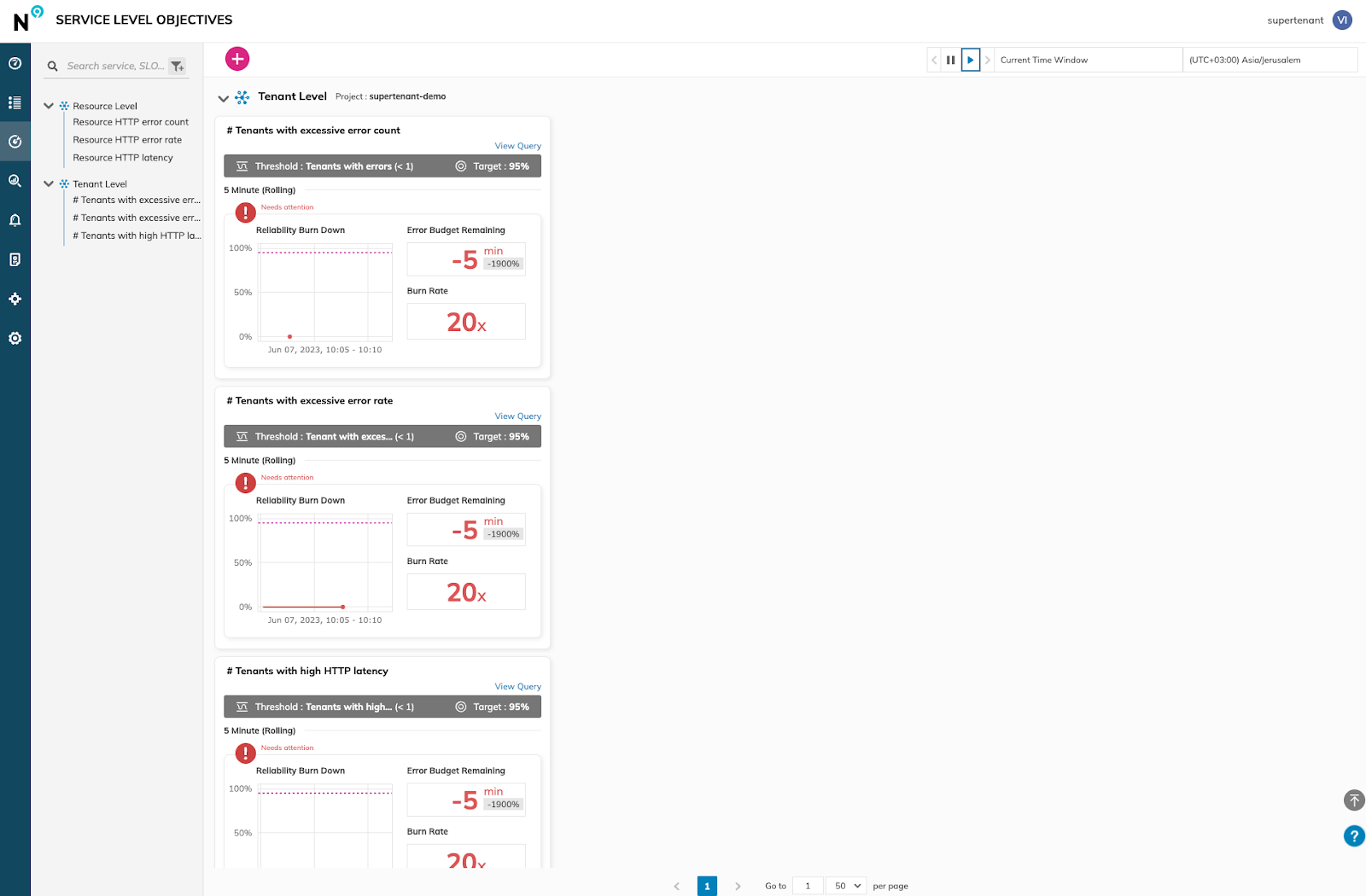
The first step to remediation of an issue is monitoring and measuring. With Nobl9+SuperTenant, it’s easy to see and get notified of SLO breaches per tenant.
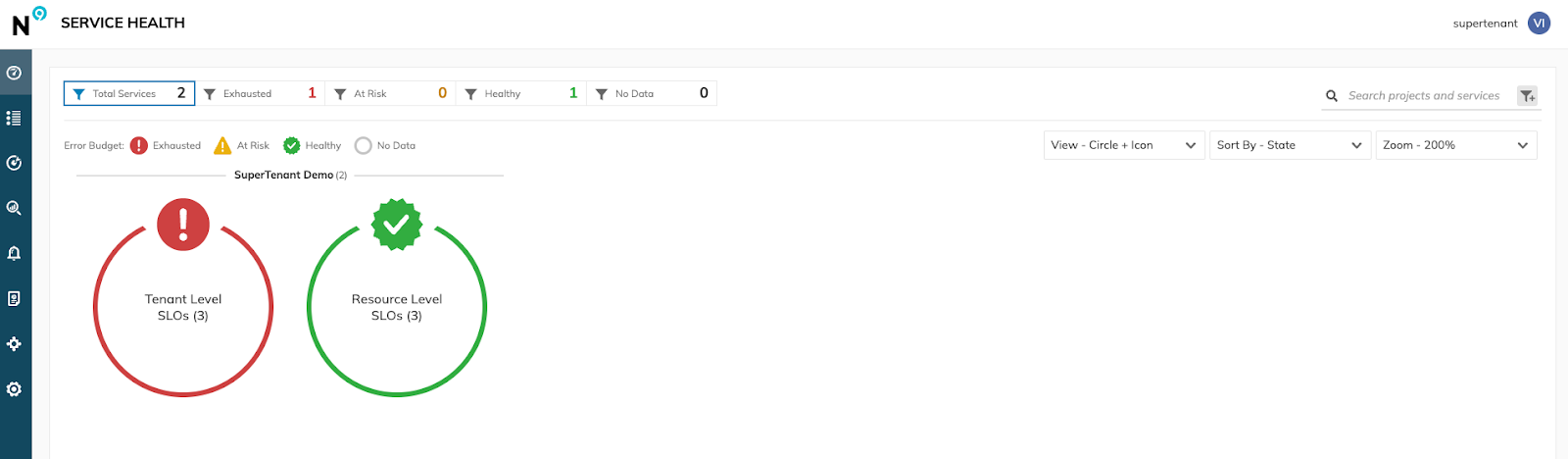
Once a breach of SLO is identified, there are multiple approaches to mitigation, many of which can be done by SuperTenant, and specifically tenant QoS. This will be covered in a separate blog post.
Conclusion
The importance of tracking SLOs at the customer level cannot be overstated. By focusing on individual tenant performance, businesses can gain a deeper understanding of their service's effectiveness across cost, optimize resource allocation, and ultimately deliver a better experience to their customers. The combination of SuperTenant's tenant-centric technology and Nobl9's expertise in software reliability offers a powerful solution for businesses striving for improved SLO management.
As we've discussed, the integration between SuperTenant and Nobl9 enables a comprehensive view of tenant and service-level SLOs, providing valuable insights that can drive better business outcomes. It's not just about managing SLOs, but also about leveraging them as a strategic tool for enhancing user happiness, avoiding churn, and aligning with business KPIs.
We invite you to explore the potential of tenant level SLOs first hand, schedule a quick demo of SuperTenant or get started with the free edition of Nobl9.
Share:







Do you want to add something? Leave a comment