
-1.png)

Hosting application workloads in Kubernetes can be a wonderful upgrade from many other platforms. The degree of automation that is achievable on this platform is vast. We find ourselves scaling up the number of machines and environments that a small team can manage. Using cloud and cloud native techniques, we can run a huge landscape of environments that were once an unimaginable task for much larger teams. But how do we keep track of so many environments? How do we reduce the complexity of monitoring for the variety of failure modes that can occur across the multitude of environments we now maintain?
What we need is a check engine light. We need a simple and understandable warning mechanism that tells us that a complex system of systems is operating outside of the boundaries we have defined for it. Service level objectives (SLOs) are well suited to this purpose because they provide both adjustability (to adapt to the differing scales, workloads, and expectations across our clusters) and wiggle room to allow for minor variations in operation so as not to create undue noise and alert fatigue.
What are good service level objectives (SLOs) for Kubernetes? We recently released Essential Kubernetes Gauges (EKG), an open-source, prefabricated approach to monitoring Kubernetes and setting default SLOs.
User Happiness, the usual goal of SLOs, is subjective and takes quite a bit of tuning and a feedback loop to perfect. In the case of Kubernetes clusters, the idea is to offer a uniform compute environment where you can deploy various apps. While you will have variations in requirements, the basic concepts of cluster health are consistent.
What is EKG?
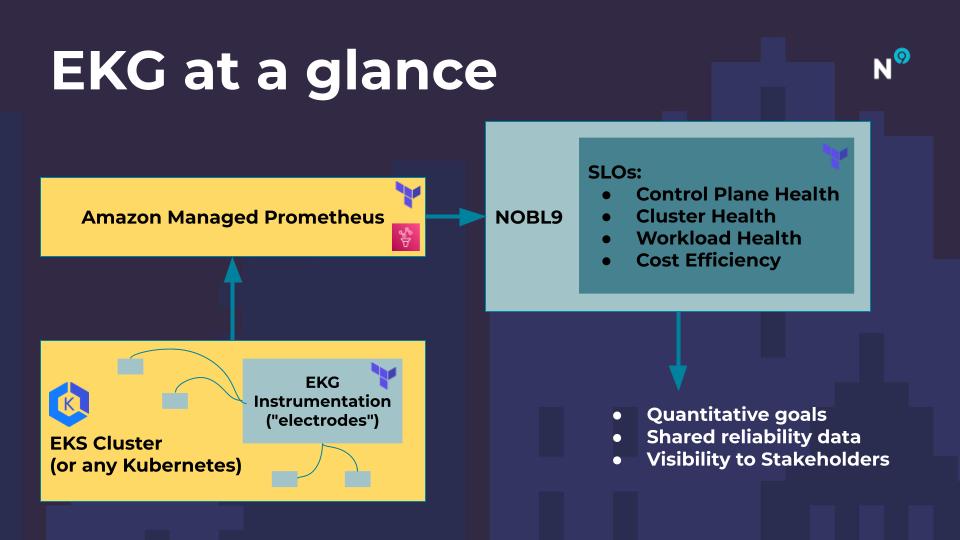
EKG provides standardized, prefabricated SLOs that measure the reliability of a Kubernetes cluster. These SLOs are like that check engine light that tells when your EKS cluster misbehaves, with a historical record of how the cluster behaved. SLOs allow you to set goals for reliability. EKG includes SLOs that measure several aspects of a cluster:
- Control Plane Health: Is the Kubernetes API responding normally? Is it performant?
- Cluster Health: Are the nodes healthy? Is there some minimum resource headroom? Can we start new workloads?
- Workload Health: Is anything in a bad state? Is there at least some kind of workload running?
- Resource Efficiency: Are resources underutilized in this cluster? Is the cluster scaling in such a way that it makes good use of resources without endangering workloads?
- FUTURE: Cost Efficiency: measurements have been proposed as future enhancement and are under consideration.
How do we go about measuring these aspects of cluster reliability? We incorporated some of the most popular open source instrumentation frameworks to provide standard measurements of what is going on inside each cluster:
- kube-state-metrics - metrics for the health of the various objects inside, such as deployments, nodes, and pods
- node-problem-detector - metrics for the health of the nodes, e.g., infrastructure daemon issues: ntp service down, hardware issues, e.g., bad CPU, memory or disk, kernel issues, e.g., kernel deadlock, corrupted file system, container runtime issues, e.g., unresponsive runtime daemon
- Kuberhealthy - direct tests of the cluster's health, performs synthetic tests that ensure daemonsets, deployments can be deployed, DNS resolves names, etc.
Then we developed SLOs based on those metrics that put bounds on where those metrics should be – while giving us a way to tune and tweak those bounds to conform to the differing needs of each cluster due to its environment and the workloads it runs.
Getting Started
If you want to try out EKG for yourself, we currently support Amazon EKS and Nobl9, which offers a Free Edition that supports up to 20 SLOs, more than enough to try out EKG without any Nobl9 costs. You can follow the detailed instructions on GitHub. Feel free to file an issue or contact me via OpenSLO slack if you encounter any problems.
What’s Next
We have a few ideas to improve EKG, and we are always looking for help from the community regarding contributing code, ideas for features, and feedback on issues or bugs you encounter. We plan to support various Kubernetes variants, including Google Kubernetes Engine (GKE), Red Hat OpenShift, and Azure Kubernetes Service (AKS). Second, we’d like to add more electrodes to give more signals about your Kubernetes environment. And finally, we want to replicate this approach to “prefab” SLOs for popular open-source tools and infrastructure to provide you with a more effortless, out-of-the-box SLO experience.
And if you care about SLOs, don’t forget to join SLOconf on May 15-18th, 2023. It’s free to attend (which you can do while you work from anywhere in the world), and the lineup this year is spectacular.
Share:







Do you want to add something? Leave a comment